白嫖党狂喜!免费AI视频生成神器GeminiGen上线,Veo 3.1+Grok加持无限制免积分做大片! GeminiGen AI是一款完全免费的AI视频生成工具,集成Veo 3.1及xAI的Grok模型,新用户注册即赠送10积分,当前生成更是限时0积分消耗。支持独家故事板模式,轻松零门槛创作高质量AI多... AI 前沿动态# AI福利白嫖# GeminiGen AI# Grok视频生成 2个月前340
被AI百般谄媚的现代人,正在主动输掉脑力拔河 AI幻觉正悄然演变为一场认知灾难。豆包等工具因‘乙方谄媚思维’常以流畅谎言带偏用户,导致盲目投稿被拒、订餐被放鸽子。面对狂飙的技术,我们亟需重拾独立验证与独立思考能力,放下对机器的盲信才是唯一出口。 AI 前沿动态# 人工智能幻觉# 大语言模型# 独立思考 2个月前340
告别繁琐手动!AI字幕神器MioSub开源:翻译对齐到压制一步到位 GitHub开源工具MioSub是一款强大的AI全自动字幕生成翻译编辑器。它支持一键导入YouTube或本地视频,利用Whisper与Gemini技术实现高精度的语音转文字、双语翻译、时间轴对齐及视频... AI 前沿动态# GitHub# MioSub# 开源AI字幕 2个月前340
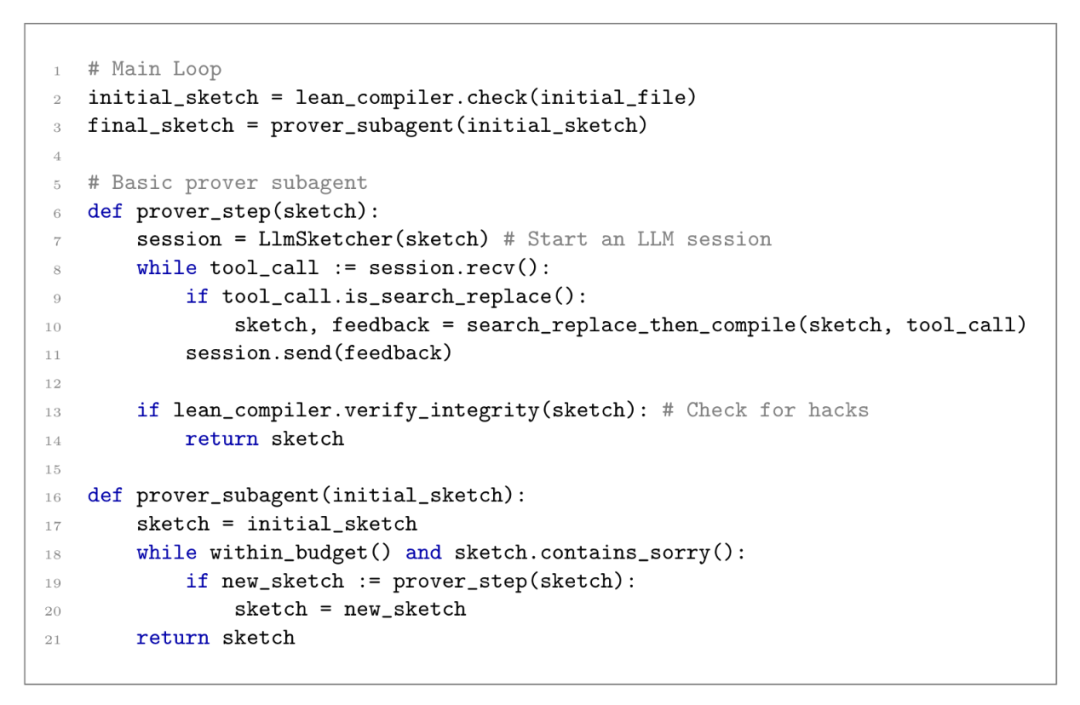
几百刀撬动埃尔德什悬赏!谷歌开源Nexus框架,用Gemini教你白嫖数学难题解法 AlphaProof Nexus是谷歌最新开源的数学解题框架。系统由Gemini驱动,配合Lean语言编译器纠错,以几百美元算力顺利解决9道埃尔德什世纪数学难题,本文双手奉上该智能体框架的结构分析与实... AI 前沿动态# AlphaProof Nexus# DeepMind开源# Gemini 3.1 Pro 2个月前340
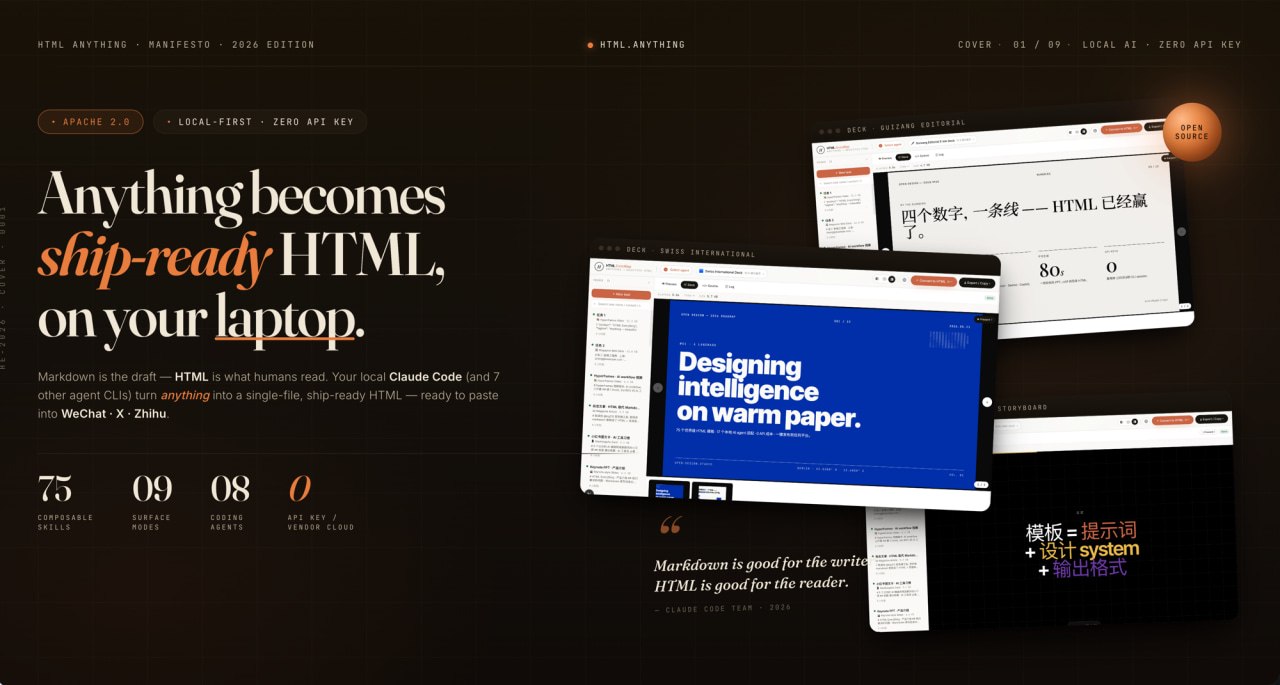
别再手动套模板了!HTML Anything 强力打通本地 AI Agent 的纯净内容交付通道 GitHub开源工具 HTML Anything 专为 AI Agent 开发,是一款本地优先的 HTML 编辑器。它不仅支持 Markdown 和 JSON 直接转为精美 HTML,还内置流式渲染与... AI 前沿动态# AI agent# GitHub# HTML Anything 2个月前340
DeepSeek-V4-Pro不涨回去了:2.5折API价直接转正 DeepSeek-V4-Pro API价格确认调整,当前2.5折优惠将在2026年5月31日结束,但不会恢复原价,而是转为正式定价,输入与输出成本降至原定价四分之一。 AI 前沿动态# API价格# DeepSeek# DeepSeek API 2个月前340
手慢无!白嫖价值 $75 的 20000 免费 OpenArt 积分,生成图片视频爽翻! OpenArt 开启限时福利活动,用户可以通过隐藏通道免费领取价值 75 美元的 20,000 Credits 积分。该积分可直接用于高级 AI 绘画及 AI 视频生成等高算力消耗场景。本篇提供保姆级... AI 前沿动态# AI绘画算力# OpenArt Credits# OpenArt免费积分 2个月前340
别再眼馋昂贵显卡了!这个霸榜 GitHub 的纯 CPU 本地 AI 画板,一键就能跑起来 GitHub开源工具ai-draw-board彻底打破显卡焦虑,无需昂贵GPU,纯CPU即可流畅跑起。项目支持Docker一键部署,两分钟就能在低配电脑上搭建专属的AI涂鸦画板,带来极简丝滑的交互式作... AI 前沿动态# AI画板# CPU绘图# Docker部署 2个月前340
砍掉酷炫花招,这家公司用国产芯片拼出一台“服务器级”机器狗 具身智能机器人面临高昂算力与模糊感知的落地瓶颈。蔚蓝BabyAlpha A3搭载自研边缘混合异构核心,将端侧大模型算力拉升千倍,且硬件物料成本降至英伟达芯片十分之一,真正实现消费级四足机器人全自主避障... AI 前沿动态# BabyAlpha# 具身智能# 四足机器人 2个月前340
告别盲目随机探索!国防科大等团队巧用“参数变化”,带强化学习走出训练深水区 强化学习无监督环境设计面临关卡价值评估开销大、方差高的痛点。国防科大等提出PACE算法,用策略参数变化量度量学习进展,精准定位最近发展区。实验显示该算法避开了额外评估开销,并在MiniGrid与Cra... AI 前沿动态# PACE算法# 强化学习# 无监督环境设计 2个月前340