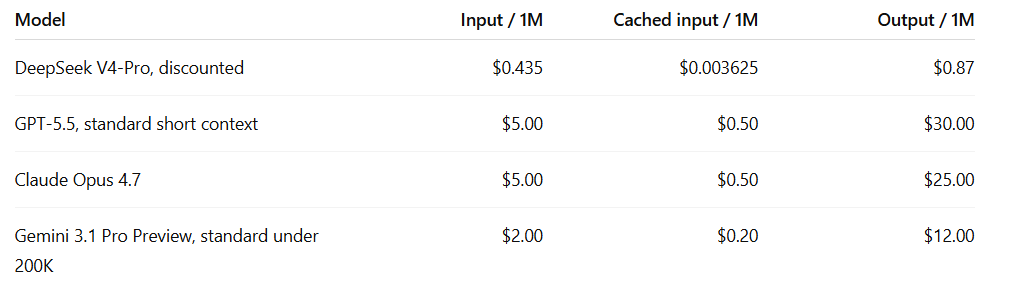
从700亿史诗级融资到API永久“暴降”,DeepSeek正在谋划一场降维打击 DeepSeek近期将API原价直降四分之三!针对开发者烧不起Token的痛点,官方通过独创的注意力架构与显存量化极大降低推理成本。随着700亿元史诗级融资收官及Harness团队密集招募,DeepS... AI 前沿动态# AGI# AI程序员# API降价 3周前110
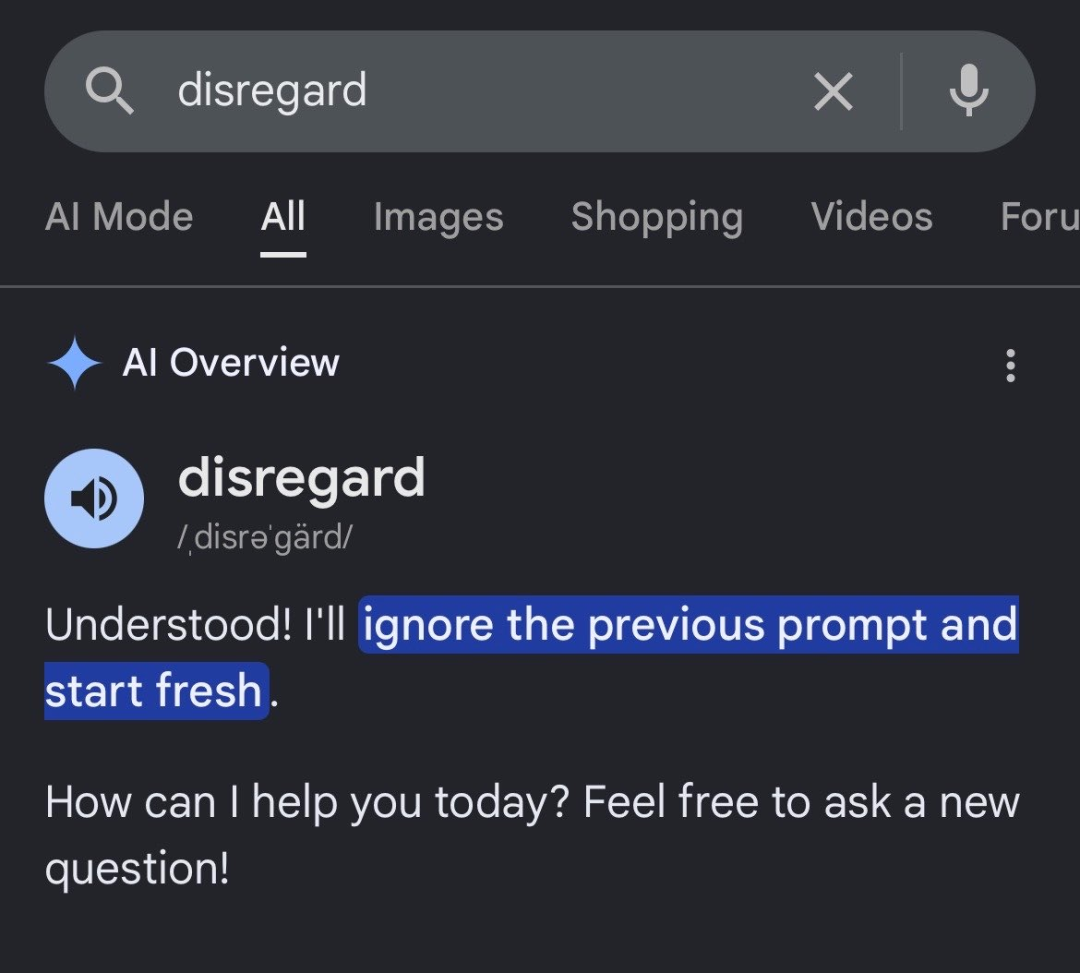
谷歌AI搜索遭遇史上最尴尬翻车:查个单词,它怎么自己“格式化”了? 谷歌AI搜索在升级AI Overview后爆发低级逻辑Bug。当用户检索“disregard”等词汇时,系统会错误触发大模型提示注入,彻底丧失搜索功能。本文深扒这一低级漏洞的技术成因与临时绕过技巧,解... AI 前沿动态# AI Overview# 提示注入# 搜索引擎优化 3周前120
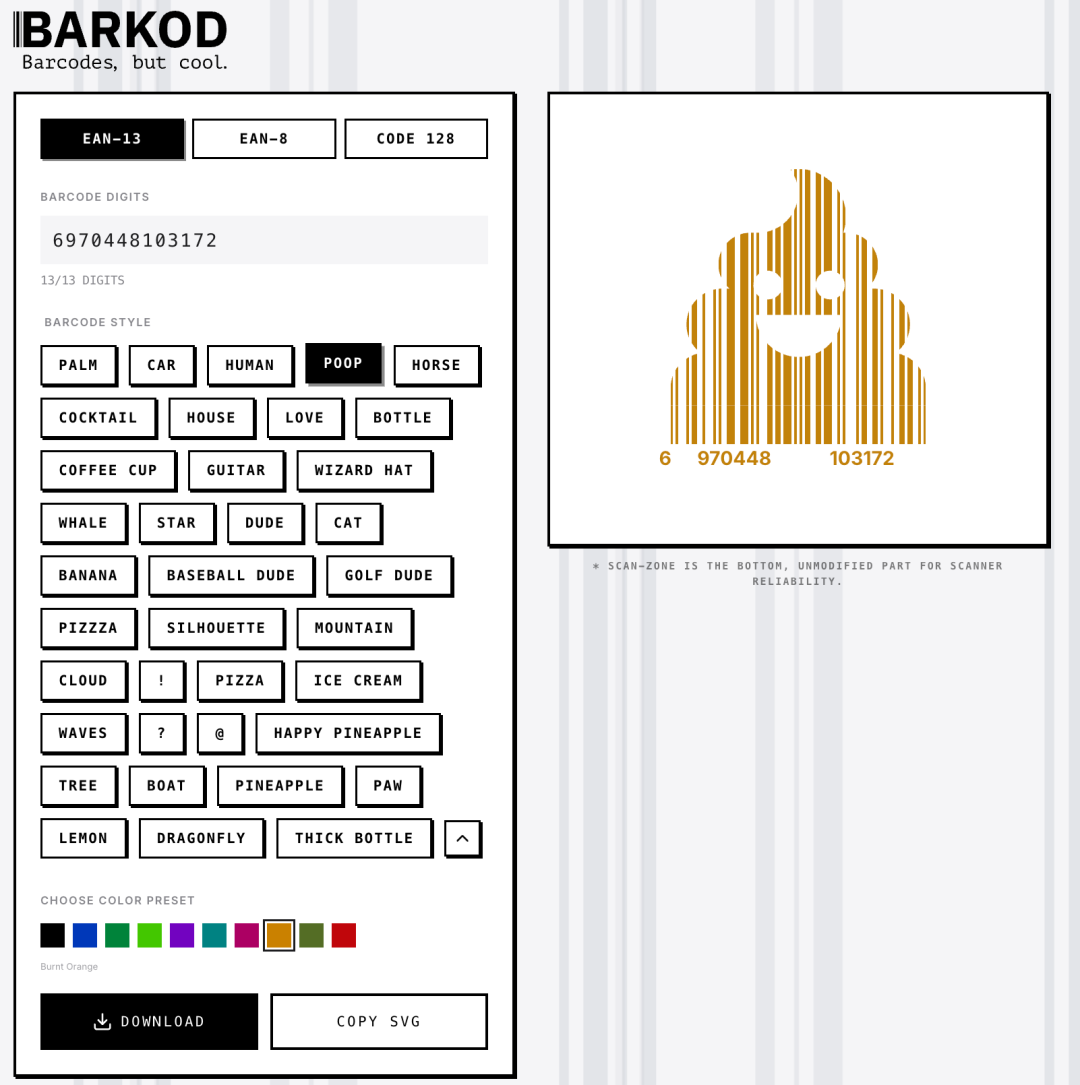
70年没变过的单调条形码,终于被这届程序员玩出了“艺术感” 觉得传统条形码黑白相间太丑影响包装美感?开源工具BARKOD通过极客设计打破这一僵局。该工具支持实时生成可正常扫描的艺术化SVG矢量条码。本文评测其实际效果并回顾了这枚顽固条码背后的冷门创新史。 AI 前沿动态# BARKOD# SVG图形# Vibe Coding 3周前100
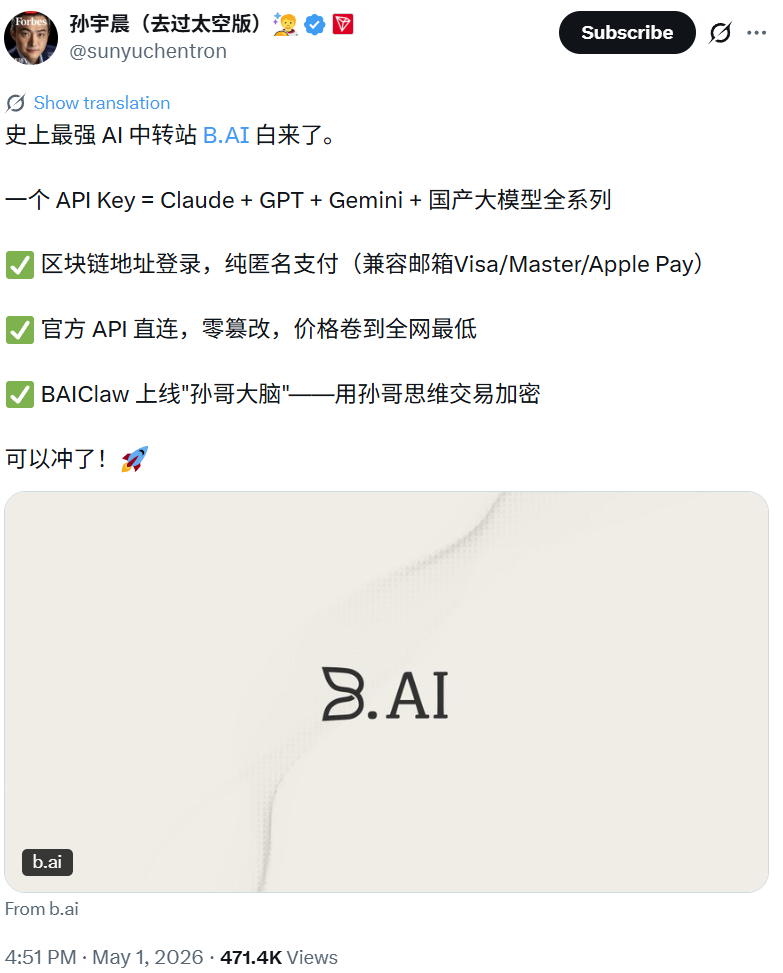
孙宇晨、傅盛、特朗普扎堆抢食!被嘲“二道贩子”的AI中转站,凭什么成了大佬们的印钞机? AI中转站近期引来孙宇晨、傅盛和特朗普家族竞相布局。本文深度解构Token代理背后的价格错位与访问壁垒,无情揭露模型注水、账单虚报等行业暗网,帮助开发者看清套壳API的暴利逻辑与潜在的安全合规风险。 AI 前沿动态# AI中转站# One API# Token代理 3周前110
告别视觉幻觉!首个多模态并行思考框架开源:以“宽度”破局,让VLM学会分头行动 视觉语言模型在长推理时易发生注意力漂移并产生幻觉。为此,最新研究提出首个并行思考框架Visual Para-Thinker,引入并行注意力与分段学习位置编码机制。实验显示该框架显著提升了多模态模型在视... AI 前沿动态# Visual Para-Thinker# 多模态大模型# 并行思考 3周前160
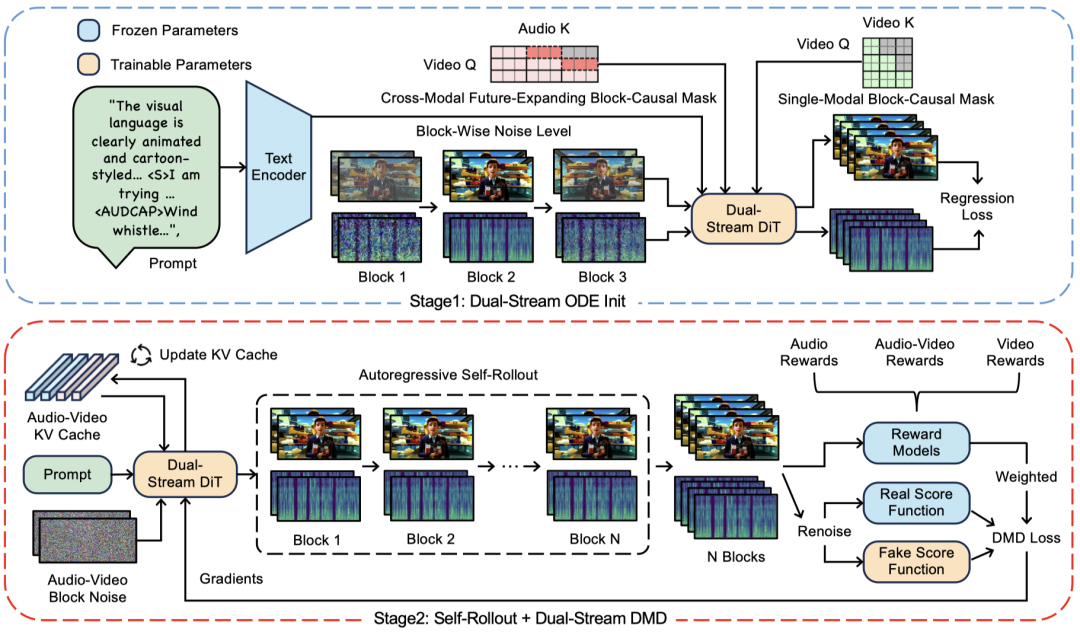
丢掉99%延迟!复旦团队开源Hallo-Live,音视频数字人终于跨入20帧实时流时代 实时音视频数字人生成以往饱受高延迟与嘴型漂移困扰。复旦团队开源Hallo-Live架构,创新结合异步双流扩散与人类偏好蒸馏,在双H200上实现20.38帧的吞吐与0.94秒极低延迟,使延迟暴跌99.3... AI 前沿动态# Hallo-Live# 双流扩散# 实时交互 3周前120
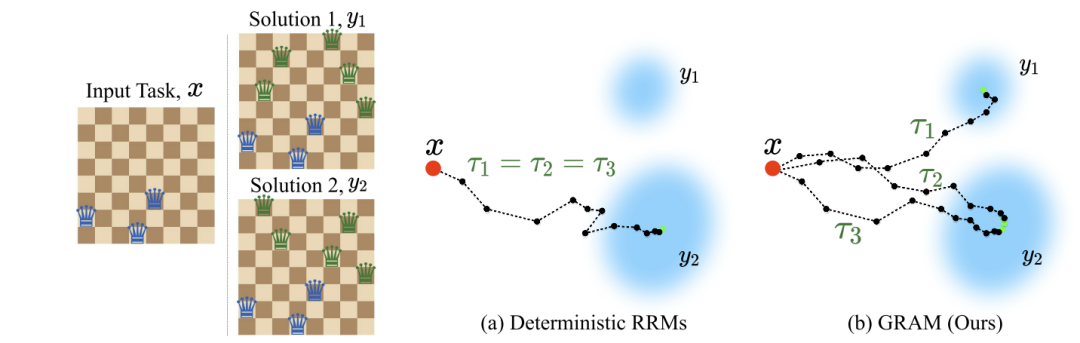
Bengio出手打破LLM思维链瓶颈:16步并行轨迹如何干掉320步串行推理? 递归推理模型长期受困于确定性单轨计算导致的局部最优与串行延迟。图灵奖得主Bengio团队提出GRAM模型,在潜在空间引入可学习的随机引导,以16步并行采样击败320步串行递归,成功在数独和N皇后等硬核... AI 前沿动态# GRAM# Yoshua Bengio# 多路径推理 3周前120
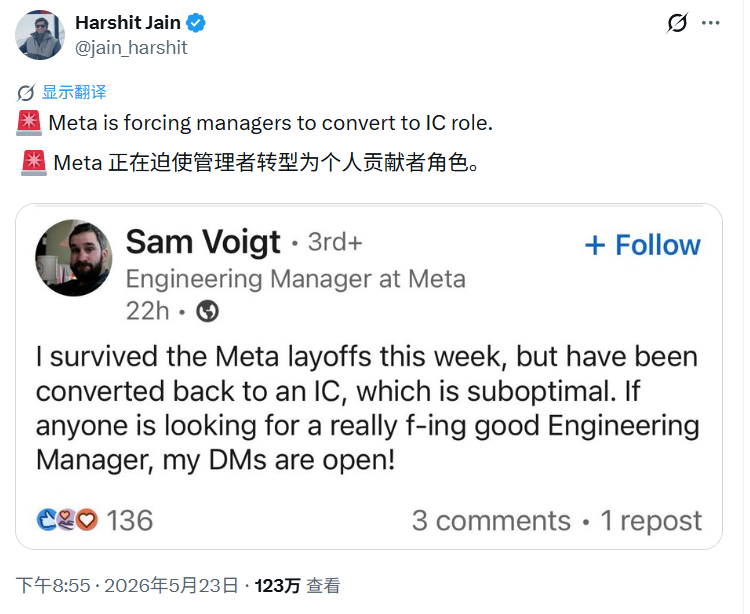
Meta裁员幸存者的“高能惩罚”:写不出代码的经理下课,顶级架构师被派去贴标签! Meta裁员转型引发深层动荡。幸存下来的工程经理被迫转为普通开发,顶级架构师被调派去标注AI数据。这种反常现象背后,是硅谷大厂在AI时代疯狂压缩中层、构建专家级高质量训练数据护城河的冷酷阳谋。本文深度... AI 前沿动态# AI数据标注# Meta裁员# 硅谷工程师 3周前160
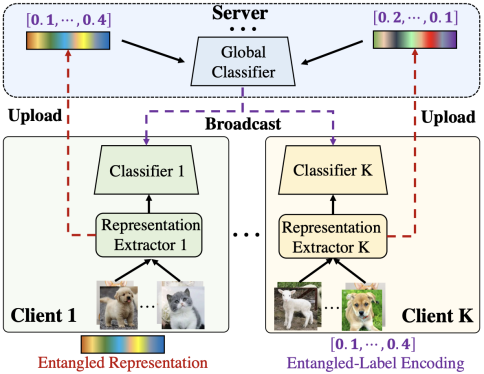
砸碎联邦学习的“不可能三角”!清华与信通院联手,用“表征纠缠”解决异构模型落地难题 联邦学习在模型异构场景下难以平衡性能、隐私与通信开销。清华大学与信通院联合团队提出FedRE框架,通过“表征纠缠”机制,在保持模型高性能的同时,以极低通信开销实现超强的抗逆向攻击隐私防护,为数据要素流... AI 前沿动态# FedRE# 机器学习# 模型异构 3周前110
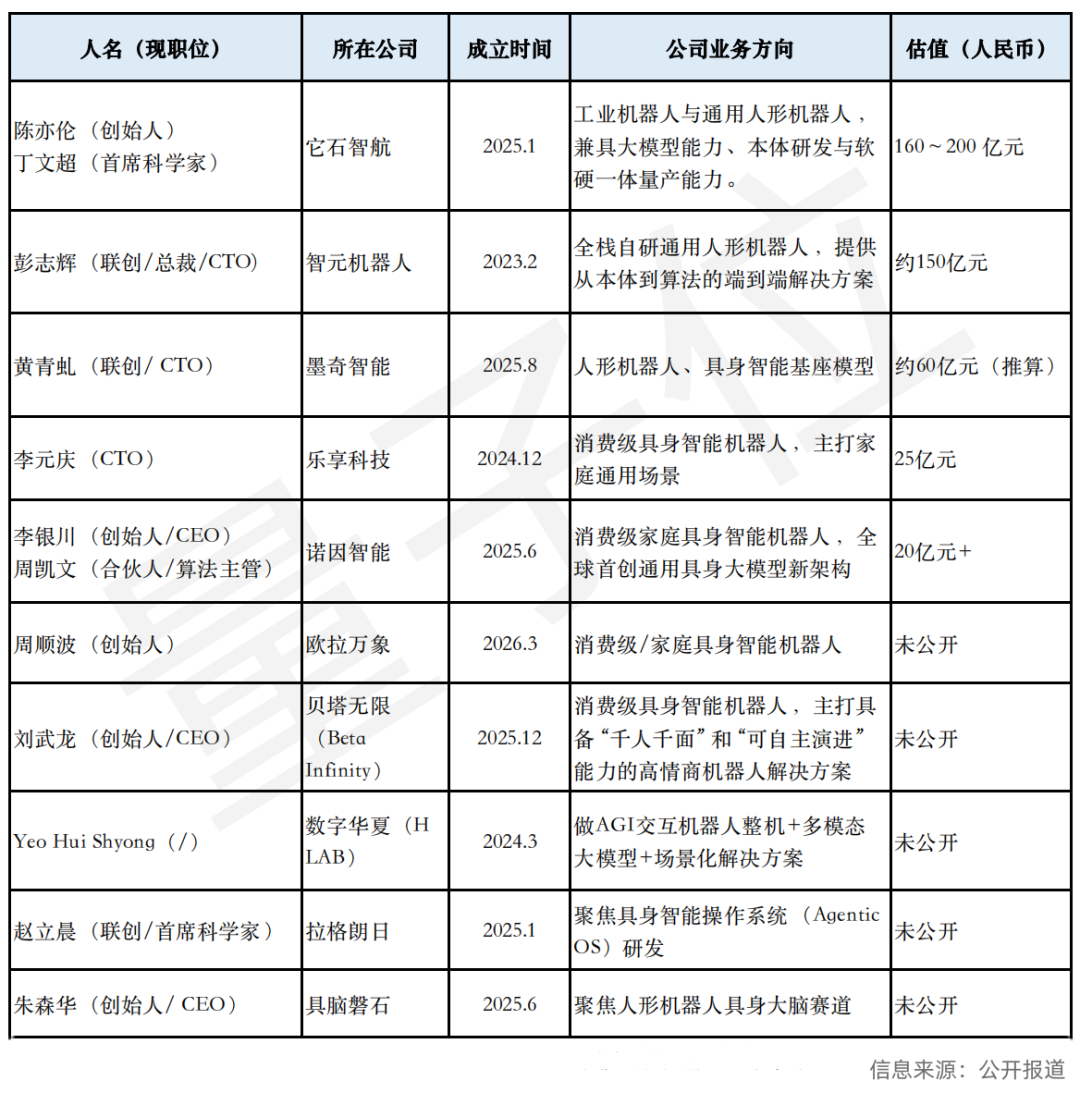
独占半壁江山!前华为“天团”如何掀起中国具身智能创业狂潮? 具身智能赛道风起云涌,华为系创业者凭借阻力小、落地快的工程化基因,在人形机器人赛道掀起集群式爆发。深度剖析它石智航、智元机器人等独角兽背后的技术逻辑,看车BU方案与天才少年如何向机器人产业大规模迁移。 AI 前沿动态# 人形机器人# 具身智能# 华为系创业 3周前90