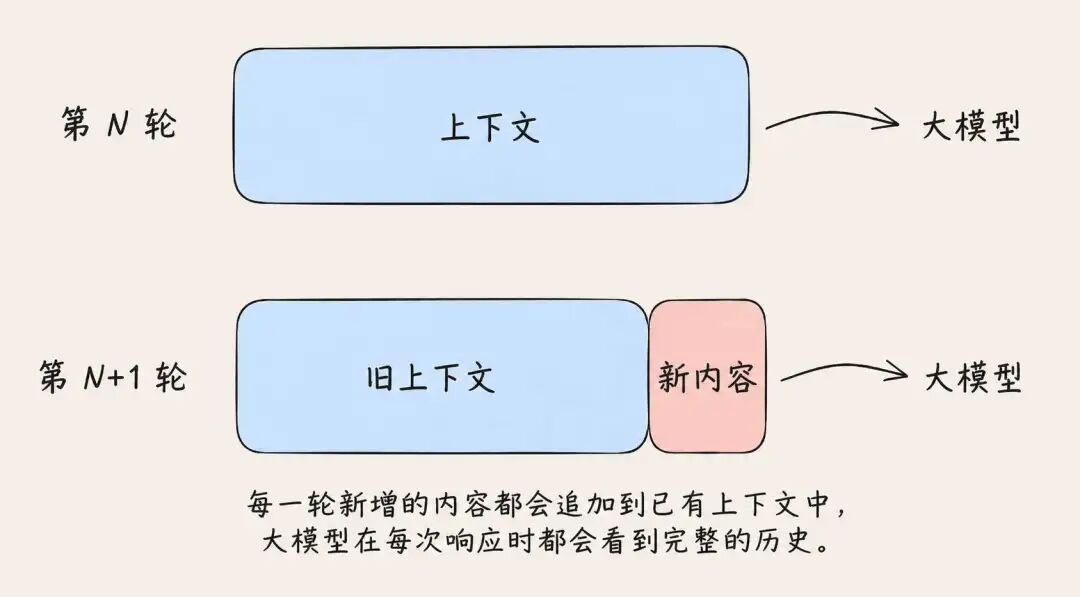
AI Agent 降本超 80% 的绝对核心!彻底搞透 Prompt Caching 运行机制与省钱实战 深度解析 Prompt Caching(提示词缓存)的工作原理与底层逻辑。从 Transformer 的 Prefill 与 Decode 阶段出发,拆解 KV Caching 机制,并以 Claud... AI 前沿动态# AI agent# Anthropic省钱# Claude Code 3周前130
面壁智能发布MiniCPM-SALA:稀疏-线性混合架构,9B模型端侧跑通百万上下文,速度飙升3.5倍 面壁智能推出MiniCPM-SALA,基于稀疏-线性混合注意力架构,仅9B参数即可在消费级GPU上处理百万词元上下文,推理速度达同类模型的3.5倍,长文本能力领先且保持通用性能。 AI 前沿动态# MiniCPM-SALA# OpenBMB# SALA架构 4周前130
原力灵机范浩强:评判机器人好坏的唯一指标,是它多久能回本 原力灵机联合创始人范浩强在访谈中提出,评判机器人好坏的唯一指标是它多久能回本。本文深入探讨了具身智能真实场景的落地挑战,以及原力灵机如何通过开源模型与硬件闭环,从百里挑一走向无限泛化。 AI 前沿动态# DFOL# RoboChallenge# 具身智能 4周前130
全模态AI智能体新基准OmniGAIA:360道地狱级任务,测出开源模型真实水平仅13分! 人大与小红书联合发布OmniGAIA基准,360个高难度任务评估全模态AI智能体长程推理与工具调用能力,开源最强模型仅13%准确率,提出OmniAtlas训练方法大幅提升性能。 AI 前沿动态# Gemini-3-Pro# OmniAtlas# OmniGAIA 4周前130
CVPR 2026 Oral | 清华阿里联手推出 ViT³:用六大设计原则重塑视觉 TTT,线性复杂度模型性能登顶 清华大学与阿里团队在CVPR 2026上提出纯TTT架构ViT³,通过六条设计原则系统构建高精度视觉测试时训练模型,在多项视觉任务中超越线性注意力与Mamba,为长序列建模提供新基线。 AI 前沿动态# TTT# ViT³# 序列建模 4周前130
从打工妹到国宴C位:周群飞凭什么坐进苹果和特斯拉的牌桌? 周群飞,蓝思科技创始人,15岁辍学打工,靠两万港币起家,如今坐在库克和马斯克之间。从摩托罗拉V3到iPhone,从智能手机到智能汽车,蓝思科技如何成为全球巨头的核心供应商? AI 前沿动态# 周群飞# 国宴# 库克 4周前130
独家|年利润数千万,睿尔曼智能获5亿元C轮融资,具身智能赛道首个盈利玩家! 睿尔曼智能完成5亿元C轮融资,2025年净利润数千万元,实现盈利。全栈自研四大核心部件,产品性能领先,年产能10万台,获CR L3认证,客户包括智元机器人等。 AI 前沿动态# 5亿元# C轮融资# 一体化关节模组 4周前130
估值直逼禾赛!凭一双灵巧手走红,Sharpa如何蜕变为具身智能整机独角兽? 从春晚盘核桃到CES发布整机North,Sharpa凭借直驱灵巧手技术震惊业界,估值超十亿美元。本文深度解析这家由禾赛创始团队组建的具身智能新贵的崛起路径与战略布局。 AI 前沿动态# CraftNet# North# Sharpa 4周前130
一个月烧掉130万美元Token!龙虾之父自曝账单,OpenAI全包 龙虾之父Peter Steinberger一个月消耗6030亿Token,费用高达130万美元却由OpenAI承担。揭秘其背后的自动化开发体系与Tokenmaxxing现象。 AI 前沿动态# AI费用# Codex# OpenAI 4周前130
Token天价账单下的技术突围:端云协同与记忆优化如何拯救AI Agent? 2026年,AI Agent的Token消耗成为行业痛点。本文深入剖析端云协同架构与记忆操作系统两大技术路线,探讨如何实现安全、成本与智能的平衡。 AI 前沿动态# Agent# GAIR Live# Token焦虑 4周前130