国产GPU里程碑!摩尔线程MUSA原生入驻SGLang,DeepSeek V4已全面打通 摩尔线程MUSA后端正式合入SGLang主线,成为全球顶级开源推理框架的原生支持硬件。DeepSeek V4已完成端到端适配,多模型覆盖,零代码迁移,国产算力正式跻身AI基础软件核心圈。 AI 前沿动态 3个月前0390
RHTV实测:原生AI智能体画布如何让创作小白秒变导演?全程干预、告别盲盒 RunningHub推出原生AI智能体平台RHTV,将Agent与画布深度融合,支持自然语言驱动短剧、电商物料等专业创作,全程可视化、随时干预,背靠十万级生态无上限。 AI 前沿动态 3个月前0390
阿里千问小酒窝惊艳亮相:从聊天到办事,AI生活搭子时代来临! 阿里发布生态级AI助手“千问小酒窝”,以数字人形象融入千问App,未来将接入淘宝等全生态,实现谈心和办实事一体化,标志着阿里AI迈入场景化落地新阶段。 AI 前沿动态 3个月前0390
追长篇网文不再靠脑补:ColorTxt 把角色高亮、剧情梳理和 AI 读书塞进本地阅读器 GitHub开源工具ColorTxt把本地小说阅读、内容上色、AI剧情解读和听书功能放在一起,适合追长篇网文时管理角色、道具、伏笔,并支持 macOS、Windows、Linux 多平台使用。 AI 前沿动态# AI阅读# ColorTxt# GitHub 2个月前380
彻底告别网络依赖!这款纯本地、支持OCR的Android开源翻译器有点强 开源工具 Offline Translator 是一款专为 Android 打造的纯本地离线翻译应用。该软件完全在设备端运行,无需联网即可进行多语种文本互译,并支持强大的图片 OCR 文字识别、TTS... AI 前沿动态# Android应用# GitHub# OCR识别 2个月前380
拒绝信息焦虑!这个开源导航站一口气收录千款AI神器,连GitHub开源趋势都帮玩家打包好了 GitHub开源工具导航站AIHub为你提供全新的一站式AI生态探索体验。项目不仅深度收录了超千款精选AI工具,覆盖对话、绘图、音视频等16大主流细分领域,还整合了热门开源趋势排行与每日科技前沿资讯... AI 前沿动态# AIHub# AI导航# GitHub 2个月前380
免费开源!快手Keye-VL-2.0-30B大模型上线:手把手教你白嫖256K超长视频理解与代码Agent Keye-VL-2.0-30B-A3B是快手开源的全新一代多模态大模型底座。它引入了DSA机制以极低推理成本支持256K超长上下文,并首次解锁Code与Tool等Agent协作机制,提供优秀的时序因果... AI 前沿动态# Agent# Keye-VL-2.0# 多模态大模型 2个月前380
京东JoyInside现场干货:AI不只会聊天,要钻进玩具、机器人和你家床垫里 JoyInside正在把京东JoyAI大模型植入玩具、机器人、台灯、床垫等家庭硬件,目标2026年底覆盖超千万台终端,本文整理现场重点、产品方向和参与入口。 AI 前沿动态# AI World# JoyInside# 京东AI硬件 2个月前380
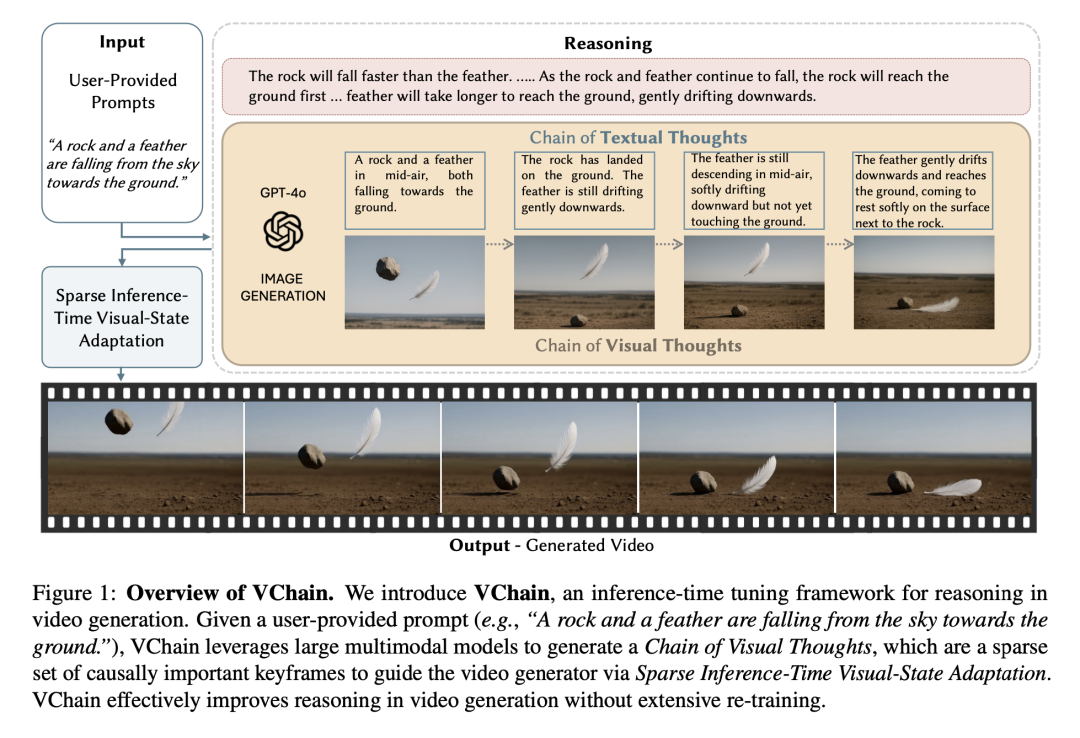
给视频生成装上“物理外脑”:NTU团队提出VChain,用视觉推理解决画面“穿帮”难题 视频生成模型常因缺乏物理常识导致画面穿帮。南洋理工大学团队推出VChain框架,首次引入“视觉思维链”机制。该方案利用多模态大模型进行逻辑推演并指导视频生成,在常识与因果规律测评中表现优异,零重训实现... AI 前沿动态# VChain# 多模态大模型# 大模型推理 2个月前380
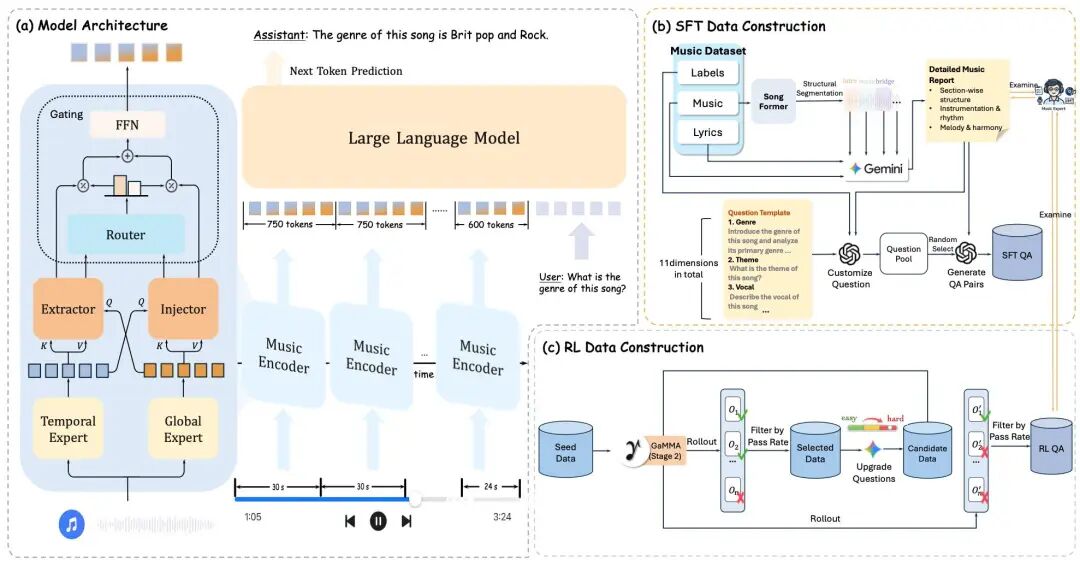
读懂音乐时间线到底有多难?复旦与字节联手打造GaMMA,多模态大模型终于学会“按秒听歌” 音乐时序理解一直是多模态大模型的致命短板。复旦联合字节推出GaMMA模型,创新采用双编码器融合网络与GRPO强化学习,让大模型真正读懂音乐时间线。实验表明,它在音乐结构拆解与时序任务上超越Gemini... AI 前沿动态# GaMMA# GRPO强化学习# 多模态大模型 2个月前380